Dataframes with Pandas
Sorry, we're not learning about the adorable black-and-white bear in this lesson, but instead we're learning about the Pandas python module (short for "Panel Data") that will let us visualize data inside of python.
Dataframes
You might have used the a spreadsheet program like "Excel" in the past to organize data. Data in those programs is organized into rows and columns, so that you can easily find the information that you're looking for. In the spreadsheet below, each of the rows is a different country, and each of the columns is different information about that country.
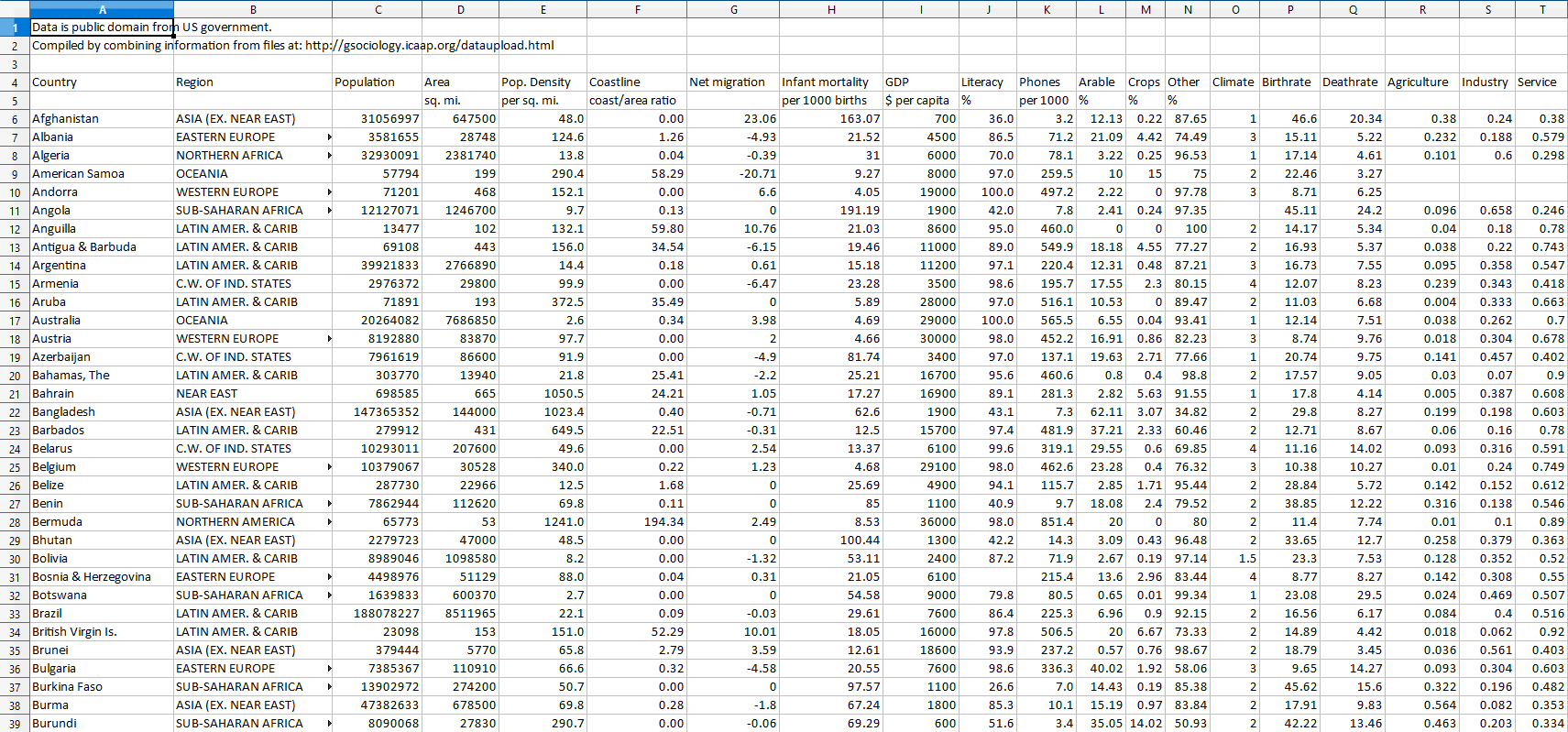
Pandas works in a similar way. Data is organized into columns and rows so that it is easy to understand, called a Dataframe.
For this lesson, we're going to be working with a data set of Pokemon. Pokemon are a type of creature that appears in the Pokemon video games. (Wikipedia Entry) Each Pokemon has specific powers that players use to battle other players, called "trainers".
Create a new file called "pokemon.py", and import the pandas module at the top of the file.
import pandas as pd
Here we use import as to abbreviate the pandas namespace to pd.
Next, we'll learn how to import data into a dataframe in python.
Importing CSVs
Download the CSV (Comma-separated Values) file here: Pokemon.csv
To download the file, right-click on the link and select Save link as...
Then in the pop-up window, go to the same location as your 'pokemon.py' file, and click Save.
A CSV file is a text file that is organized into rows and columns. The separation between columns is indicated by a comma, and the separation between rows is indicated by a newline.
We'll start by reading in the information in Pokemon.csv by using pandas' read_csv() function. This function returns a dataframe, so we'll store it in a variable and print it out to see what the dataframe includes.
import pandas as pd
poke = pd.read_csv('Pokemon.csv')
print(poke)
By printing out the dataframe, we're given a couple key pieces of information.
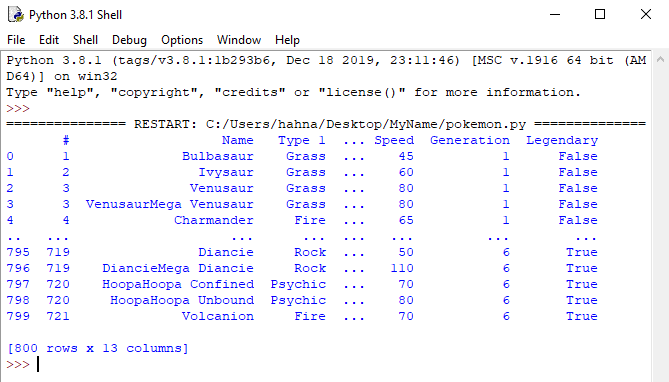
The top row shows the Column Names. We'll use these to reference individual columns when we want to see that information.
You'll notice the first column of the result does not have a name. This column is called the index. This is just the row number.
At the bottom of the file, you see the total number of rows and columns that were present in the CSV file we read. For this file, it was 800 rows and 13 columns. This is called the Shape of the data.
After the 4th column and the 5th row, there are three dots ..., and then you see three more columns, and 5 more rows! But shouldn't our file have 800 rows? Where did they go? Well, pandas knows that printing out the ENTIRE data set might make things hard to read, so it tries to give us a simpler way to view the data by only showing us a limited set.
There are other ways to view data as well:
1. The head() function will show rows of data starting from the top of the dataframe. You can add a number as an argument to the function to see a specific number of rows, otherwise it will show you the top 5 rows.
2. The tail() function will show rows of data starting from the bottom of the dataframe. You can add a number as an argument to the function to see a specific number of rows, otherwise it will show you the bottom 5 rows.
Try adding these functions to your python file and running the code. Using head and tail, you can see more about the data.
print(poke)
print(poke.head())
print(poke.head(20))
print(poke.tail())
print(poke.tail(30))
print(poke.head(20))
There are other ways for us to look at this dataset as well.
1. The info() function shows us information about the entire dataframe. This is helpful to see all of the column names and what type the column is. It will also tell us how many null values the column has.
2. The describe() function tries to summarize all the columns of the table, which can be helpful for information like finding the mean (average) of all values of a column. Based on the output of the describe function, we can know that the average Speed of a pokemon is around 68.
First, try using the info() function.
print(poke.info())
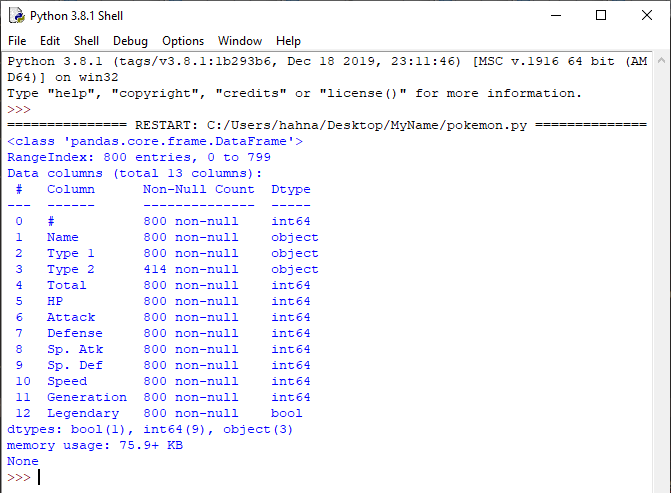
1. In this dataframe, each pokemon's name is present in the "Name" column.
2. The "Type 1" column shows the primary type of the pokemon, and the "Type 2" column shows the secondary type. Since not all pokemon have secondary types, some of these values are blank, or null. There are 414 pokemon that have a value in the Type 2 column.
3. There are 6 columns related to the pokemon's individual stats, the "HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", and "Speed" columns. The higher these values are, the more powerful the pokemon is.
4. The "Total" column is the sum of the individual stat columns for the pokemon.
5. The "Generation" column shows which version of the pokemon game they were first seen in. Based on the output of the describe function, we know that the values of this column go from 1 to 6.
6. The "Legendary" column is a boolean value, which means it is either True or False. If this value is True, it indicates a pokemon that is especially rare and powerful.
2. The "Type 1" column shows the primary type of the pokemon, and the "Type 2" column shows the secondary type. Since not all pokemon have secondary types, some of these values are blank, or null. There are 414 pokemon that have a value in the Type 2 column.
3. There are 6 columns related to the pokemon's individual stats, the "HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", and "Speed" columns. The higher these values are, the more powerful the pokemon is.
4. The "Total" column is the sum of the individual stat columns for the pokemon.
5. The "Generation" column shows which version of the pokemon game they were first seen in. Based on the output of the describe function, we know that the values of this column go from 1 to 6.
6. The "Legendary" column is a boolean value, which means it is either True or False. If this value is True, it indicates a pokemon that is especially rare and powerful.
Next, let's try the describe() function.
print(poke.describe())
The describe function shows different summary values for the dataframe. E.g. count, mean, min, max, etc.
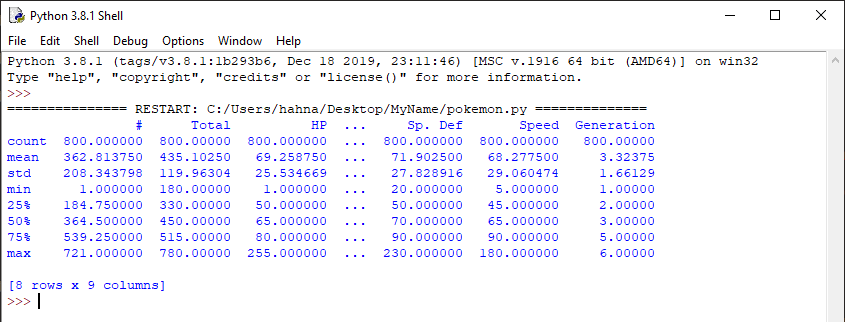
By looking at the output of describe(), we can see that the minimum "Total" value is 180, the maximum "Total" value is 780, and the mean (average) "Total" value is 435.10250.
These basic functions show us information about the entire dataframe, but we can use other functions to view data more specifically to find out exactly what we want to know.
Showing Specific Rows
You can view individual rows from a dataframe in the same way you get information from a dictionary.
By using the dataframe name, and then putting the column name in square brackets and single quotes, you can return information from just that column.
print(poke['Name'])
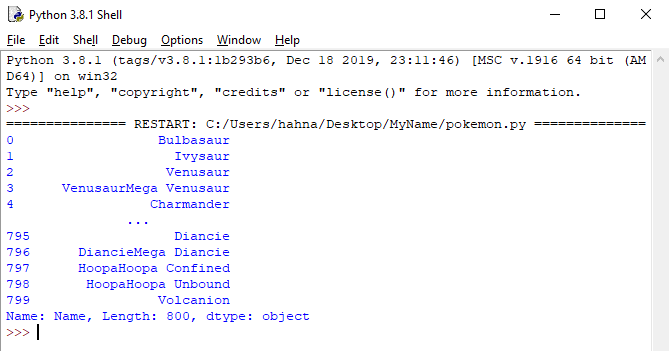
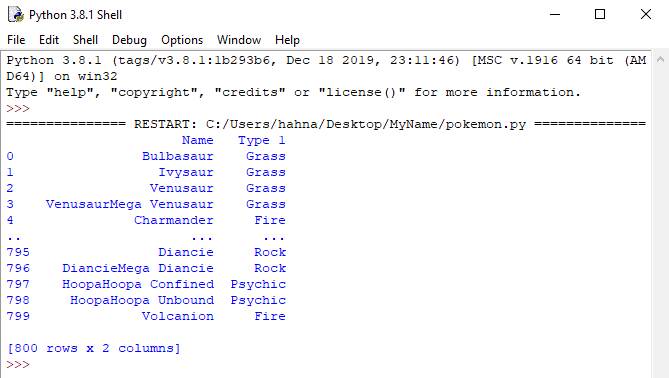
If you want to show more than 1 column at a time, you can put two square brackets around the column names and separate them with a comma.
print(poke[['Name', 'Type 1']])
You can also find data inside a data frame based on a condition. For example, in order to find information on the pokemon Pikachu, we can use the following code.
print(poke[poke['Name'] == 'Pikachu'])
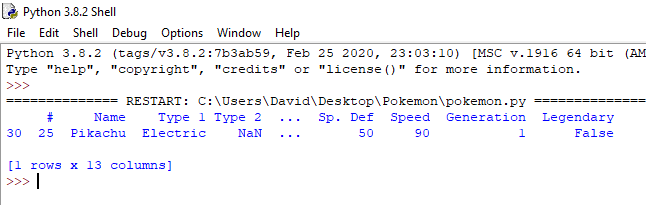
This code can be read like this: "Get all rows from the poke dataframe where the name value for the row equals Pikachu". This is called a Filter.
The outside of the dataframe is poke[] and the condition for which rows to return is poke['Name'] == 'Pikachu'
We can also select rows inside a dataframe by checking for specific values in a column. Try the below functions and see what you find out about the data set.
#Will return all rows where the 'Name' column contains the word "Mega"
print(poke[poke['Name'].str.contains('Mega')])
#You can add a '~' in front of the condition to reverse it; this will only show pokemon without "Mega" in their name
print(poke[~poke['Name'].str.contains('Mega')])
#Will return all rows where the 'Speed' column is greater than 120
print(poke[poke['Speed'] > 120])
#Will return all legendary pokemon from generation 1, use the '&' symbol between conditions to have more than one criteria for selection
print(poke[(poke['Generation'] == 1) & (poke['Legendary'] == True)])
Now that you understand the basic tools of filtering, next we'll cover how to use groups to really narrow down your data into what you want to know about the pokemon in this data set.
Data Manipulation
We're going to learn how to group, analyze and sort data.
Pandas has data aggregation functions we can use to simplify the way we see data. We've learned how to get subsets of our data frame based on conditions, but we can transform those subsets into simpler information that shows exactly what we want to know.
For example, how many pokemon are there of each of the different types? We can learn this by using a groupby() function, followed by a count() function. We are going to organize the information into groups based on the different 'Type 1' values.
print(poke['Type 1'].groupby(poke['Type 1']).count())
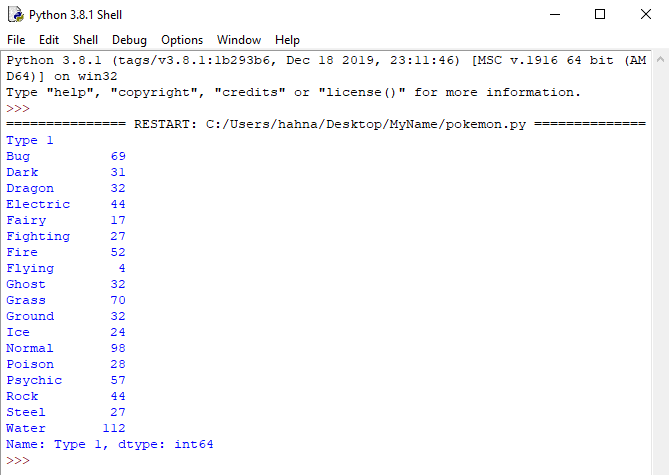
Now we know how many pokemon have different primary types. But it would help if it was better organized. What are the most common types? That's where the sort_values() function comes in handy.
print(poke['Type 1'].groupby(poke['Type 1']).count().sort_values(ascending=False))
By specifying ascending=False as an argument in the sort_values() function, the sort will be from largest to smallest.
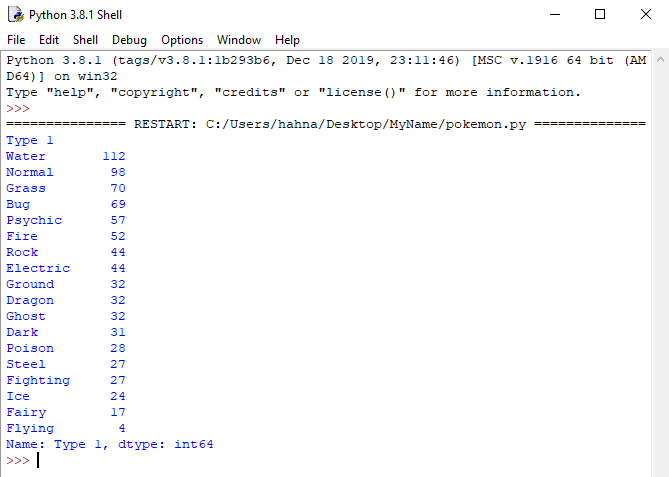
As you can see, the function calls on our poke dataframe are starting to get fairly long, and they can be hard to keep track of as they grow longer
One way we can make this simpler is by saving the result of our dataframe into a variable.
poke_power = poke[['Total', 'Name', 'Type 1']].sort_values(by='Total',ascending=False)
This new dataframe just contains the columns for the total stats for the pokemon, its name, and its primary type. We've also sorted all pokemon by their total power.
With this simpler dataframe, we can add more filters and groupings to gain more insight without having a neverending line of code. For example, what is the most powerful pokemon of each type?
poke_power = poke[['Total', 'Name', 'Type 1']].sort_values(by='Total',ascending=False)
# Will show the most powerful pokemon of that type
print(poke_power.groupby('Type 1').first())
# Will show the least powerful pokemon of each type
print(poke_power.groupby('Type 1').last())
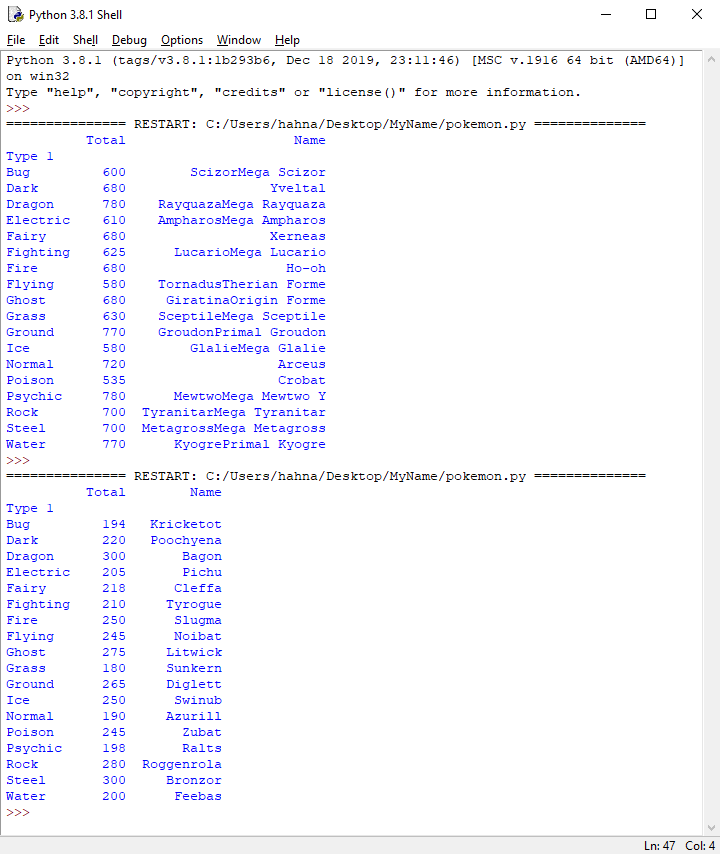
Next, we're going to learn how to clean up our data.
Data Cleanup
Sometimes we need to clean up the data in a data set before we use it. We can save our changes back to the original variable we are using, or create a new variable to store our cleaned data.
For example, sometimes an individual pokemon has multiple records because they have multiple "forms", but we just want to have that pokemon listed once in our data set.
print(poke[poke['Name'].str.contains('Mewtwo')])
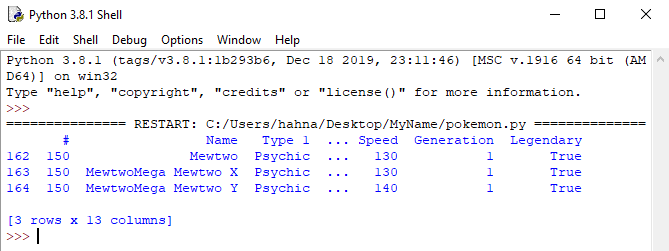
We can get a list where there are no duplicate pokemon by using the drop_duplicates() function, and removing any pokemon that have a duplicate '#' field.
no_duplicates_poke = poke.drop_duplicates('#', keep='first')
print(no_duplicates_poke[no_duplicates_poke['Name'].str.contains('Mewtwo')])
Challenge: Pokemon
A pokemon team is comprised of 6 pokemon. In this challenge, you'll create a team of the most powerful pokemon using your data science skills. Then, you'll fine-tune your team based on specific parameters.
If you can master the skills of data science, rather than spending hours looking through your data by hand, a simple one-line change can get you the information that you need.
1. First, select the pokemon with the top 6 stat totals (hint: use sort_values() and head()).
2. New requirement, no legendary pokemon allowed. Before sorting and getting the top 6 results, remove legendary pokemon from the list.
3. New rule: All pokemon on the team must have a different primary type. (hint: use drop_duplicates).
Now you have a team ready to become the next pokemon master! But before you win the pokemon championship, there's another pokemon trainer that could use your data science skills...